这是一篇CCFB的文章,来自中科大,文章提出了一种新的二进制混淆模式来抵抗binary diffing技术的分析。
从混淆角度,它是从IR层面切割函数并融合函数,改变了函数的调用关系。与OLLVM是不冲突的混淆,对抵抗binary diffing有很好的效果,并且也是基于LLVM框架,对混淆技术的发展是有意义的。
背景
binary diffing
binary diffing是一种识别两个二进制差异的技术,可以通过识别两个二进制之间差异的技术。它可以给出预定义粒度(如函数)的匹配结果。例如bindiff提取了基本块,控制流边和函数调用数量作为函数的特征,然后它节后控制流图匹配算法搜索相似的函数。
现有的漏洞挖掘方法中,很常见的一个方法是通过对比新旧版本,找出不同处,这些修改处很可能是以及修补的漏洞。通过binary diffing可以快速定位新旧版本中的修改处,从而进一步分析漏洞。现在这种技术常用在分析1day/nday的情况,是一种高效的分析手法
软件混淆
现在做混淆很多都基于中间指令(IR)来做,比如ollvm的各种魔改。或者做指令虚拟化(VM),但指令虚拟化会导致性能大量损失。所以本文也是对IR做混淆。
一般现在的IR混淆粒度,都是继承自ollvm的三种粒度。
- 指令级:复杂化指令,把一条指令换成多条
- 基本块级:设置虚假控制流与基本块
- 函数级:通过函数扁平化,把函数结构转化为难以分析的
switch-case结构
随着binary diffing的发展,许多程序内粒度的静态代码重写技术不在有效。主要是程序内代码混淆不会从根本上改变每个函数的语义,而大多数binary diffing都是越来越能提取函数内部特征来理解语义。
Khaos 设计
Khaos是在IR层面,增加混淆,通过分裂原本的函数,并融合成新的函数。
oriFunc:原始函数。
sepFunc:裂变函数,分裂原始函数形成的裂变函数。
fusFunc:聚变函数,融合后形成的新的函数。
remFunc:剩余函数,剩余代码形成的函数。
例子:
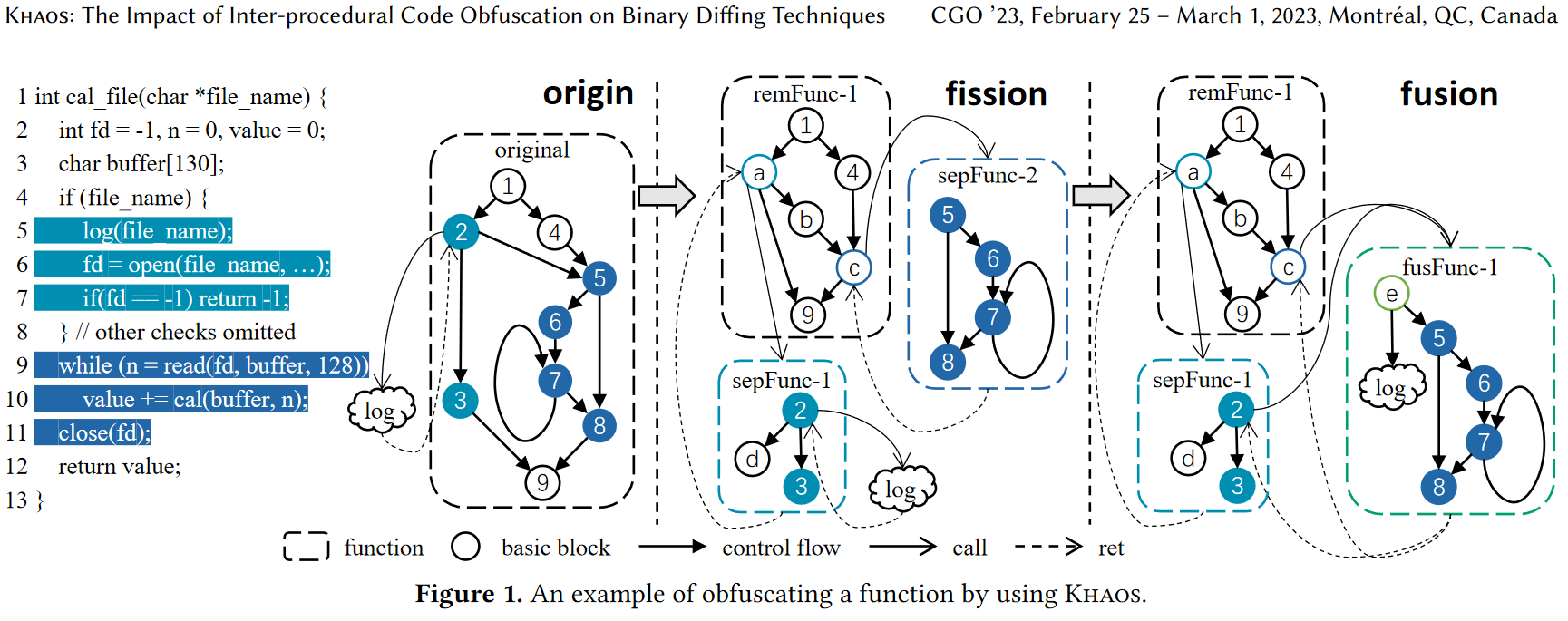
困难
困难1:选择那些基本块或者函数聚合/分离,平衡开销与混淆效果。
困难2:如何在转换后完全重建函数间的所有控制流
困难3:简单融合函数,在编译器优化后,混淆效果有限。
分割形成sepFunc
对代码区域划分转换成一个图形切割问题,函数的控制流图可视为有向图,边的权重代表执行频率,表示冷/热信息。代码区域划分可以看作图的切割,切割边的权重是性能代价,混淆效果是子图中节点的数量。
基于上述思想提出区域识别算法,来平衡混淆效果与性能
-
首先,我们将对函数的支配树进行分析[40](第 2 行)。
-
为了避免将整个函数体分离成一个 sepFunc,我们删除了函数本身的支配者树(第 3 行)
-
并从其他树中识别出区域。为了说明裂变对混淆的影响,我们使用树中基本块的数量来表示(第 7 行)。
-
为了说明裂变对性能的影响,我们使用块频率分析法来计算支配者树根节点的执行频率(第 8 行),并使用循环次数(如果区域处于循环中,则对 sepFunc 的调用将增加)作为切割的成本(第 8-12 行)。
-
我们会反复选择性价比最高(即效果和成本之比最大)的支配树进行分离,直到树集为空(第 13-16 行)。
数据流重建
除了切割区域作为sepFunc,还需要将函数入口与出口定义出来,也就是这一段带来使用的oriFunc中的局部变量。如果这个变量只有这个sepFunc使用,那么函数参数就可以不要,直接重新在sepFunc中定义局部变量即可。
控制流重建
把sepFunc在oriFunc中的跳转关系改为call-ret的关系,不同的函数出口返回的基本块也不同(这是与正常返回函数效果不同的地方)。
对于异常处理控制流,把可能触发异常的代码与catch块放到同一个sepFunc来保证不破坏异常处理的逻辑。
融合函数
融合函数理论上可以多个函数融合到一起,但是作者从性能角度考虑,选择两个函数融合到一起,融合主要看函数的返回值参数数量与类型是否一致,遵循下面几条原则
- 函数变量不确定的不融和,比如
printf(....) - 函数返回值类型不兼容的不融合
- 直接调用关系的两个函数不融合
前两个主要满足正确性,最后一个是为了性能考虑,否则很容易产生大量递归的fusFuncs。满足上述条件的sepFuncs将随机成对
数据流重建
选择完两个函数后,可以很直接的将两个函数合并,然后通过一个ctrl变量来控制数据进入fusFunc的那一部分,如图三中所示。

同时,由于直接合并两个函数会导致参数数量过多,所以会尝试压缩函数的参数,具体就是会将第一部分中所使用的参数同时运用第二部分相同/类似参数处,如图三的c部分,将原本的参数short a, int m转换成int x,在调用short a中的部分直接(short) x来转换成short类型变量。
控制流还原
一旦创建fusFunc,就删除原本的两个oriFunc,同时设置ctrl参数,并在调用处修改参数对应位置与值。
处理间接函数调用就比较难分析,文章提出标记指针,其实就是类似静态污点分析,从IR层面上的污点分析类似源码层面,所以间接调用的情况能基本全部分析出来。
但是除了间接调用,还有跨模块的调用。跨模块调用只有两种情况。一个是一个模块的函数指针是传播到其他模块,另一个是其他模块的模块直接调用导出的函数。
无论是那种情况,都需要遍历fusFunc中所有涉及的模块,以保证fusFunc被正确调用。但是有的时候是没法遍历所有模块,比如有的模块是没有源码的,只是一个二进制模块。
文章提出了一种蹦床机制来解决上述问题。首先先识别所有可能的函数指针,然后添加一段蹦床代码并修改这些函数指针跳转到蹦床代码,当调用这些函数指针时,先跳转到蹦床代码,然后蹦床代码函数会帮忙重组函数参数并调用不同的fusFunc。如图4的c部分
深度混淆
文章提出一种进一步提升混淆效果的方法。文章定义经常被使用并且不影响全局功能的基本块叫“无毒基本块”。通过将来自不同oriFunc中的无毒基本块聚合在一起,加入到fusFunc中来提升混淆效果。
无害函数定义:1. 只能操作局部遍历。2. 不调用外部函数
如图5中BB3和BB6都是无害基本块,于是在这两个oriFunc合并成fusFunc时,BB3和BB6合并成一个基本块。这样大大增加了两者的混淆度,不再是一个if{...}else{...}包裹两个部分的代码了。
虽然文章这么说,但是怎么区分BB3和BB6的代码呢,毕竟还是执行不同的逻辑?考虑到是从IR层面,那就不涉及到寄存器与变量覆盖的情况,这种思路是可行的。
裂变与聚变结合
两者结合使用可以增强混淆效果,分三种模式用于测试数据
- FuFi.sep: 只聚变裂变产生的基本块,这种情况不用考虑间接调用情况
- FuFi.ori: 只聚变不需要分裂的oriFunc,比如只有一个基本块的函数。这种情况可以很好的平衡开销
- FuFi.all: 所有基本块都可以均匀聚合,混淆效果好,性能是第二考虑因素
评估实验
文章主要评估两个点,一个是开销变了多少,一个是混淆程度,以及两个之间的一个关系。主要选择的对比对象是OLLVM。
开销增加
开销如下图,FuFi.all增加开销会大很多,最高可以到75%。而其他开销会小很多,比如裂变和聚变大概平均只增加5%,6%的开销,少数情况还能降低开销
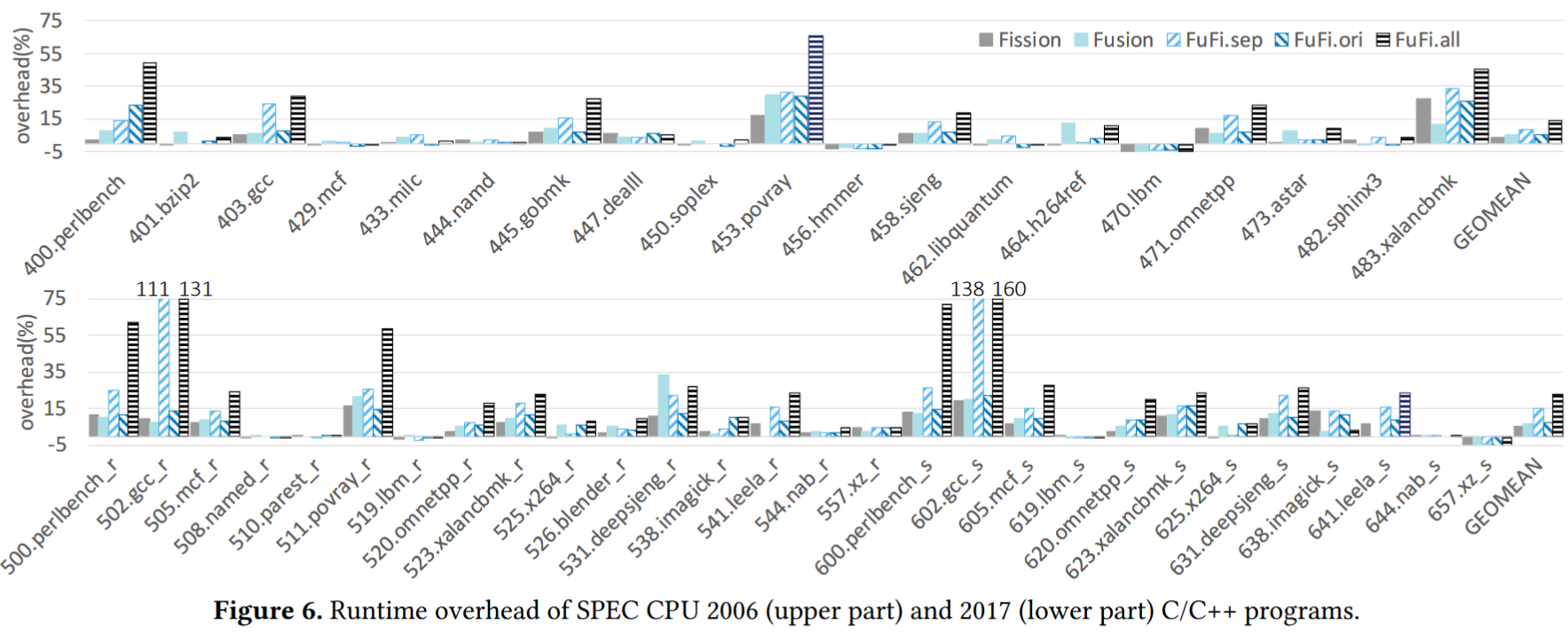
OLLVM开销对比
和OLLVM对比效果如下,OLLVM的sub,Bog模式与khaos消耗差不多,但是OLLVM的Fla会增加大量开销,khaos只有不到10%的开销增加。
两种混淆方法是不同层面上的混淆,可以用到同样的产品中
抗去混淆能力
OLLVM模式的Fla全开的话开销过大,这里只启用10%基本块的OLLVM fla模式,来确保开销想同情况下抵抗去混淆能力。
对比5中binary diffing工具的去混淆结果,这5种程序主要的分析方法如下
对比结果如下,可以明显看到,在开销相同的情况下,khao正对binary diffing技术的抵抗能力更强。
参考
[Khaos: The Impact of Inter-procedural Code Obfuscation on Binary Diffing Techniques (arxiv.org)]( https://arxiv.org/abs/2301.11586#:~:text=A prototype of Khaos is implemented based on,19%)