最近想看看binary diffing的内容,直接从头看看一篇篇翻,涉及到很多机器学习内容,很多不懂的,慢慢来看吧。这里先看了10几篇,很多都只看了一个摘要。 主要是了解一下思路,看看这个领域的内容的研究历史,Binary Diffing 1暂时只看到2016年的paper,后续继续更新,主要文章引用如下
- Bitshred: feature hashing malware for scalable triage and semantic analysis.
- Binary function clustering using semantic hashes.
- Binslayer: accurate comparison of binary executables.
- Control flow-based malware variant detection.
- {MutantX-S}: Scalable Malware Clustering Based on Static Features.
- Semantics-based obfuscation-resilient binary code similarity comparison with applications to software plagiarism detection.
- Leveraging semantic signatures for bug search in binary programs.
- Cross-architecture bug search in binary executables.
- Bingo: Crossarchitecture cross-os binary search.
- Statistical similarity of binaries.
- discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code.
- Scalable Graph-based Bug Search for Firmware Images.
- Crossarchitecture binary semantics understanding via similar code comparison.
背景
Bin diff
基本流程
- 读取两个待比较的二进制文件,例如两个可执行文件或库文件。
- 对每个文件进行静态分析,以提取其结构信息,包括函数、基本块、指令序列和控制流等。
- 将两个文件划分为基本块。基本块是一段连续的指令序列,它以分支指令(如跳转或条件分支)或函数调用为边界。
- 对两个文件的基本块进行匹配。匹配过程通常基于指令序列、操作数和控制流等特征进行相似性度量。常用的度量方法包括哈希函数、编辑距离或结构相似性指标。
- 根据匹配的基本块,生成两个文件之间的映射关系。这些映射关系表示了两个文件中相似的代码结构。
- 分析不匹配的基本块。这些基本块表示两个文件之间的差异。可以检测到代码重用、函数重命名、插入、删除和修改等操作。
- 生成可视化报告。使用图形表示来展示两个文件之间的映射关系和差异,帮助分析人员理解和比较二进制文件的结构。
函数相似度加权和:
- 25%,匹配的flow图中的边占总边数
- 15%,匹配的基本块占基本块总数
- 10%,匹配的指令数占总指令数目
- 50%,difference in flow graph MD index
整个二进制的相似度:
- 35%,匹配的flow图中的边占总边数
- 25%,匹配的基本块占基本块总数
- 10%,匹配的函数占总函数的比例
- 10%,匹配的指令占总指令数目
- 20%,difference in call graph MD index
MD index:基于函数的拓扑顺序,入度和出度的CFG哈希函数。参考 [MD-Index paper]( https://www.sto.nato.int/publications/STO Meeting Proceedings/RTO-MP-IST-091/MP-IST-091-26.pdf)
随机森林1
机器学习中有两种任务,回归和分类,而随机森林可以同时胜任这两种任务。其中分类任务是对离散值进行预测(比如将一景图像中的植被,建筑,水体等地物类型分类);回归任务是对连续值进行预测(比如根据已有的数据预测明天的气温是多少度,预测明天某基金的价格)。
N-grams2
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
文章
Bitshred: feature hashing malware for scalable triage and semantic analysis.3
tag: 2011
摘要
一个用于大规模恶意软件相似性分析和聚类的系统,并用于自动发现集群内的语义家族间和家族内关系。BitShred背后的关键思想是使用特征哈希来显著减少恶意软件分析中常见的高维特征空间。特征哈希还允许我们使用共聚类技术挖掘恶意软件家族和样本之间的相关特征
Binary function clustering using semantic hashes.4
tag: 2012
摘要
在大量二进制可执行文件中识别语义相关函数的能力对于恶意软件检测非常重要。直观上,如果两段代码对机器的状态有相同的效果,那么它们是相似的。当前最先进的工具采用各种对明智的比较(例如,使用SMT求解器的模板匹配,关键程序点的值集分析,API调用匹配等)。然而,这些方法对于大小为N的大型数据集聚类是不可动摇的,因为它们需要O(N2)比较。在本文中,我们提出了一种基于“哈希”的替代方法。我们提出了一种将函数的语义捕获为语义哈希的方案。我们的方法将函数视为一组特征,每个特征代表一个基本块的输入-输出行为。使用一种称为最小哈希的位置敏感哈希形式,可以快速识别具有许多共同特征的函数,并且将聚类的复杂性降低到0 (N)。
Binslayer: accurate comparison of binary executables. 5
tag: 2013
摘要
本文将著名的BinDiff算法与二分图匹配的匈牙利算法相融合,提出了一种计算二值图之差的多项式算法。这大大提高了匹配精度。此外,基于图编辑距离计算一个有意义的相似性度量,从中可以对二进制文件进行明智的比较。
control flow-based malware variant detection. 6
tag: 2013
摘要
本文提出了一种恶意软件相似性搜索方法,利用新颖的距离度量来检测这些变种。本文通过恶意软件包含的控制流图集来描述恶意软件特征。本文使用的距离度量是基于字符串签名的特征向量之间的距离。特征向量是将图集分解为固定大小的 k 个子图,或者是反编译后高级源的 q 个字符串。本文使用这种距离度量来执行预过滤。本文还提出了一种基于最小匹配距离的更有效但计算效率较低的距离度量。最小匹配距离使用程序反编译流程图之间的字符串编辑距离和线性和赋值问题来构建两组图之间的最小和权重匹配。本文在一个完整的恶意软件变种检测系统中实现了距离度量。评估结果表明,我们的方法在有限的误报率方面非常有效,与其他算法的检测率相比,我们的系统能检测出更多的恶意软件变种。
MutantX-S: Scalable Malware Clustering Based on Static Features. 7
tag: 静态分析,n-gram,2013
摘要
在本文中,我们设计,实现和评估了一个新的,可扩展的框架,称为MutantX-S,它可以根据程序的静态特征(即代码指令序列)有效地将大量样本聚类到族中。MutantX-S是几种新技术的独特组合,用于解决恶意软件集群的实际挑战。具体来说,它利用x86架构的指令格式,将程序表示为操作码序列,便于提取N-gram特征。它还利用最近在机器学习社区开发的哈希技巧来降低提取的特征向量的维数,从而显着降低内存需求和计算成本。我们使用超过130,000个恶意软件样本的数据库对MutantX-S原型进行了全面评估,显示其能够在2小时内正确聚集超过80%的样本,实现了准确性和可扩展性之间的良好平衡。将MutantX-S应用于不同时间创建的恶意软件样本,我们还证明了MutantX-S在预测以前未知的恶意软件标签方面达到了很高的准确性。
具体
针对恶意样本的变形,恶意样本通常会衍生成一个庞大的样本家族,在原始的上面进行拓展或修改。再每天面对成千上万疑似恶意样本的提交是,人工分析是困难的。本文通过分析静态分析原始样本,疑似样本,并提取特征,使用N-gram分析后得到相似度,可以用于大规模聚类
- 预处理,脱壳解包暴露原始指令
- 指令编码:将每条指令转化为操作码
- N-gram分析:构建特征向量以便计算程序的相似性
- 哈希:压缩特征向量,提高相似性计算速度(只对聚类的准确性造成很小的影响)
最后,在压缩特征向量的集合应用基于原型的聚类算法和分区样本到不同的集群,每个代表一组类似的恶意程序。
预处理就是从内存中提取原始指令,不适用于现在的复杂场景,比如自解码等
指令编码实际上是人工设定了一部分指令编码来代替对应的汇编指令组(比如这一些指令表示从寄存存取数据)
分析使用标准的 N-gram分析法,序列上有一个固定大小的移动窗口,窗口内容就是恶意样本内容
N-gram的N是n个子序列,对应的就是N个操作码,构建了一个|S|维的向量空间(\(|S|=|O|^N\),O是所有可能操作码的集合)的结构向量\(V\),\(V\)的每个维数是一个特定的操作码。
那么两个恶意程序\((m,v)\)的 相似性可以用向量空间中的特征向量之间的欧式距离来衡量 $$ d(m,v)=||V_m-V_n||=\sqrt{\sum_{i=1}|S|(V_m(i)-(V_n(i))^2} $$ 聚类算法
MutantX-S的目标是找到一个短时间可以处理十万个恶意软件文件,经典的分区和分层聚类没有这个处理速度。
- hash压缩向量
- 基于原型的线性时间聚类算法
基于原型的聚类效果很依赖原型的选择,使用的是Gonzalez提出的近似算法来跌带寻找原型
Semantics-based obfuscation-resilient binary code similarity comparison with applications to software plagiarism detection8
tag: 2014
摘要
现有的代码相似度比较方法,无论是基于源代码还是基于二进制代码,大多数都不能适应混淆。在软件剽窃的情况下,新兴的混淆技术使得自动检测变得越来越困难。本文提出了一种基于语义等效基本块的最长公共子序列概念的面向二进制的抗混淆方法,该方法将严格的程序语义与基于最长公共子序列的模糊匹配相结合。我们通过一组表示块的输入-输出关系的符号公式来建模基本块的语义。这样,两个区块的语义等价(和相似度)就可以由定理证明者来检验。然后,我们使用以基本块为元素的最长公共子序列对两条路径的语义相似性进行建模。这种新颖的组合导致了对代码混淆的强大弹性。我们已经开发了一个原型,实验结果表明我们的方法在实际软件中是有效和实用的。
Leveraging semantic signatures for bug search in binary programs9
tag: 2014
摘要
软件漏洞仍然构成很高的安全风险,修补已知漏洞的竞赛正在进行中。然而,特别是在闭源软件中,即使bug已经公开,也没有直接的方法(与源代码分析相反)来发现存在bug的代码部分。
针对这一问题,提出了一种基于树编辑距离的等距匹配(Tree Edit Distance Based Equational Matching, TEDEM)方法,用于自动识别与包含引用错误的代码区域“相似”的二进制代码区域。我们的目标是在与引用错误相同的二进制文件中找到bug,也在完全不相关的二进制文件中找到bug(即使是为不同的操作系统编译的)。我们的方法甚至适用于缺乏源代码和符号的专有软件系统。
分析任务分为两个阶段。在预处理阶段,通过符号简化压缩给定二进制可执行文件的语义,以使所提出方法对不同二进制文件的语法变化具有鲁棒性。其次,使用树编辑距离作为基本的以块为中心的代码相似性度量。这使我们能够在不同的二进制文件中找到相同bug的实例,甚至发现它的变体(这个概念称为漏洞外推)。为了验证所提方法的可行性,我们实现了一个TEDEM原型,它可以跨越二进制文件甚至跨操作系统边界发现真实世界中的安全漏洞,如在MS Word以及流行的信使Pidgin (Linux)和Adium (Mac OS)中。
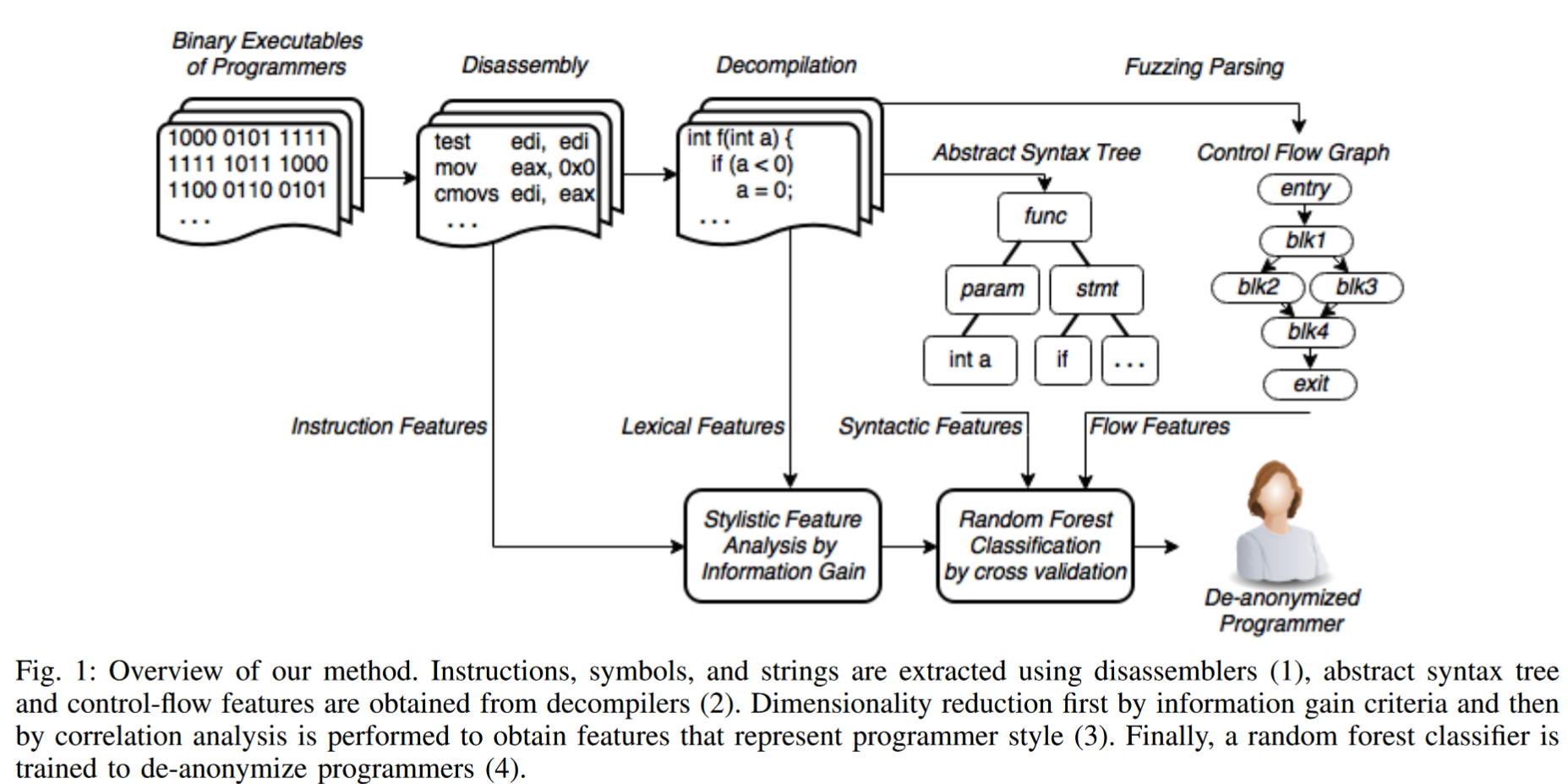
When Coding Style Survives Compilation: De-anonymizing Programmers from Executable Binaries10
tag: 2015
摘要
基于编程风格识别程序作者的能力是对程序员隐私和匿名性的直接威胁。虽然最近的工作发现源代码可以高精度地归因于作者,但可执行二进制文件的归因于似乎要困难得多。源代码中存在的许多显著特征,例如变量名,在编译过程中会被删除,编译器优化可能会改变程序的结构,进一步模糊那些在确定作者身份方面有用的特征。本文从机器学习的角度研究了程序员去匿名化,使用一组新的特征,包括通过将可执行二进制文件反编译为源代码获得的特征。采用了一套来自源代码作者归属领域的强大技术,以及汇编中嵌入的风格表示,成功地实现了大量程序员的去匿名化。 在谷歌代码阻塞的数据上评估了所提出方法,在100名和600名候选程序员中获得了高达96%的归因准确率。本文首次提出一种可执行的二进制作者归属方法,该方法对基本的混淆、一系列编译器优化设置和去掉符号表的二进制文件具有鲁棒性。我们使用混淆的二进制文件和在单作者GitHub仓库和最近泄露的这个http URL黑客论坛中找到的真实世界的代码来执行程序员去匿名化。研究表明,想要保持匿名的程序员需要采取极端的对策来保护他们的隐私。
具体
问题描述
分析人员根据纯粹的二进制程序风格来确定其程序员,程序员集合已知且对应样本,所以是一个封闭世界的有监督机器学习问题
方法
反汇编:获得基于指令码,字符串,符号信息和控制流图的特征
反编译:翻译成伪c代码,获得语法抽象树,并从中提取语法特征和n-grams
降维:有了来自反汇编器和反编译器的特征,我们通过使用基于信息增益和相关性特征选择的标准特征选择技术,选出其中对分类特别有用的特征。(因为大量的特征不能代表程序员风格,所以需要选择特征,减少分类计算过程中计算负担与过拟合的可能)。
-
使用 WEKA 的信息增益属性选择准则 。
-
特征选择:该选择方法通过考虑每个特征的单独预测能力以及它们之间的冗余程度来评估属性子集的价值。特征选择通过贪婪爬坡和回溯能力迭代进行,将与类相关性最高的属性添加到所选特征列表中。
WEKA 的信息增益属性选择准则:评估了给定特定特征的类别分布熵与类别条件分布香农熵之间的差异 [36]。
过拟合的例子:一个罕见的汇编指令可能对应一个作者,这是不准确的
分类:最后在相应的特征向量上训练森林分类器。使用 随机森林分类器。
Cross-architecture bug search in binary executables.11
tag: 2015,嵌入式,CCF-A
摘要
随着各种 CPU 架构的闭源软件的普遍可用性,需要在二进制级别识别安全关键漏洞,以执行漏洞评估。遗憾的是,现有的漏洞查找方法存在以下不足:i) 需要源代码;ii) 仅适用于单一体系结构(通常为 x86);iii) 依赖于动态分析,而动态分析对于嵌入式设备来说本身就很困难。在本文中,我们提出了一种为已知漏洞提取漏洞签名的系统。然后,我们使用这些签名来查找部署在不同 CPU 体系结构(如 x86 与 MIPS)上的二进制文件中的错误。CPU 体系结构的多样性带来了许多挑战,例如 CPU 模型之间指令集体系结构的不可比性。为了解决这个问题,我们首先将二进制代码转换为中间表示形式,从而得到带有输入和输出变量的赋值公式。然后,我们对具体输入进行采样,观察基本模块的 I/O 行为,从而掌握它们的语义。最后,我们利用 I/O 行为找到与漏洞特征行为类似的代码部分,从而有效地揭示出包含漏洞的代码部分。我们设计并实现了一种在可执行文件中进行跨架构错误搜索的工具。我们的原型目前支持三种指令集体系结构(x86、ARM 和 MIPS),并能在这些体系结构中的任何一种中发现二进制代码中的漏洞。我们的研究表明,无论底层软件指令集是什么,我们都能找到心脏出血漏洞。同样,我们还应用我们的方法在基于 MIPS 和 ARM 的路由器的封闭源固件镜像中发现了后门。
具体
工作流程
使用漏洞签名,即一段与漏洞类特定实例相似的二进制代码,来发现另一个二进制程序(目标程序)中可能存在的漏洞。为此,我们首先推导出漏洞签名。然后,我们将漏洞签名和目标程序都转换成中间表示,并构建紧凑的基本分块语义哈希值。所有这些转换对于错误签名和目标程序来说都是一次性过程。
首先将汇编代码转化为中间表示,得到一个易于解析的符号表达式,然后通过随机输入值,对这些表达式采样,得到IO对,最后对IO对简历hash值。这样就能对比基本的IO功能

在搜索阶段,我们使用转换后的漏洞签名(即其赋值公式图)来识别类似转换二进制文件中的错误。要在目标程序中为错误特征的所有单个基本模块寻找有希望的匹配候选对象。对于每一对这样的候选对象,我们都会应用一种 基于CFG 的、贪婪但局部最优的拓宽算法。该算法使用错误特征和目标程序中的其他基本块来扩展初始匹配。
漏洞签名匹配算法BHB(Best-Hit-Broadening)
BHB 的工作原理如下: 给定一对起点(签名中的基本模块和目标程序中与之匹配的候选模块)后,它首先沿着各自的 CFG 探索这些基本模块的邻近区域。在此过程中,它严格区分了前向和后向。
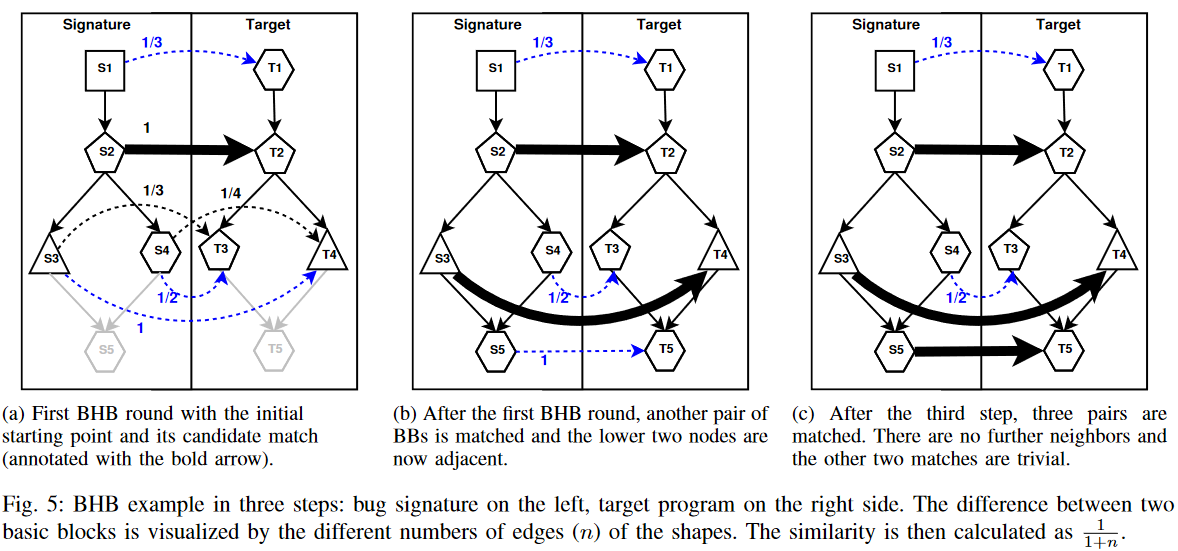
通过hash值确定相似度量,评估大量采样会生成很多IO对,匹配相同的hash值越多,说明相似度越高。
BinGo: cross-architecture cross-OS binary search12
tag: 2016, 内联函数捕获完整语义,长度轨迹跟踪,CCF-A
摘要
最近,二进制代码搜索因其在剽窃检测、恶意软件检测和软件漏洞审计等方面的重要应用而备受关注。然而,由于不同编译器、体系结构和操作系统导致二进制文件在语法和结构上存在巨大差异,因此开发有效的二进制代码搜索工具具有很大的挑战性。在本文中,我们提出了 BINGO–一个可扩展的、强大的二进制搜索引擎,支持各种体系结构和操作系统。其主要贡献在于采用选择性内联技术,通过内联相关库函数和用户自定义函数来捕捉完整的函数语义。此外,我们还提出了架构和操作系统中性函数过滤技术,以显著减少不相关的目标函数。此外,我们还引入了长度变量部分跟踪,以程序结构无关的方式对二进制函数进行建模。实验结果表明,即使存在程序结构失真,BINGO 也能以可扩展的方式找到跨越架构和操作系统边界的语义相似函数。利用 BINGO,我们还发现了 Adobe PDF Reader(一种 COTS 二进制软件)中的零日漏洞。
具体
针对三个困难点:
- 架构,编译器,操作系统差异带来的语法和结构差异。(比如memcpy在gcc下和mingw下编译差异巨大,一个没有内联,一个会内联;)
- 通过考虑完整的函数语义来实现精确性。
- 可拓展至大型真实二进制文件。
BinGo会首先内联所有库和用户自定义函数(捕获完整语义),然后选择性剪枝(图2Trace Pruning)来减少路径,避免路径爆炸。针对困难2,提出了一个专门的选择内联算法。
将汇编代码转化为IR(中间代码)来做到拓展性。设定了过滤器,可以在匹配之前去除大量不相关的函数。设定了一个函数过滤算法,目的是减少匹配的函数,提高效率。针对困难3。
提取程序的长度变量部分轨迹,在不同水平层面对函数建模(与底层架构无关)。之后可以从函数模型中提取函数语义用于函数相似性评分。针对的是困难1,下图是提取长度部分,提取长度的算法是用2014年的 David的论文
语义提取
提取部分长度轨迹后,可以从中提取语义,提取三元组\(<mem,reg,flag>\)(内存,寄存器,条件跳转位)。主要捕捉3元组前后变化状态之间的关系。可以使用约束求解(Z3)来判断语义相似度,但是真实世界使用代价巨大,所以引入了机器学习。
在轨迹剪枝的部分,还是用到了约束求解来去除一些不可到达的分支
功能匹配
利用不同的长度轨迹线来建模函数,分3中粒度(1,2,3),所有轨迹线共同组成函数模型。针对下图为例做解释
函数模型的签名为\(M_{sig} = {<1>,<2>,…,<1,2>,<2,5>,…,<1,2,4>,<2,4,7>}\)
函数模型的目标为\(M_{tar}={,,…,<a,b>,<b,c>,…,<a,b,c>,<b,c,f>}\)
支持n-to-m,1-to-1,1-to-n,n-to-1,1-to-1的匹配。计算相似度公式如下 $$ sim(M_{sig}, M_{tar}) = \frac{M_{sig}\cap M_{tar}}{M_{sig}} $$
Statistical similarity of binaries.13
tag: 2016,CCF-A,分解成更小的语义链
摘要
我们要解决的问题是在剥离的二进制文件中找到相似的程序。我们提出了一种新的统计方法来测量两个程序之间的相似性。我们的相似性概念使我们即使在使用不同编译器编译或修改过代码的情况下也能找到相似代码。我们的主要思路是通过组合使用相似性:将代码分解为更小的可比较片段,定义片段之间的语义相似性,并使用统计推理将片段相似性提升为程序之间的相似性。我们在一个名为 Esh 的工具中实现了我们的方法,并将其应用于查找各种跨编译器和版本的突出漏洞,包括 Heartbleed、Shellshock 和 Venom。我们的研究表明,Esh 的结果准确率很高,几乎没有误报–这对于在剥离的二进制文件中进行漏洞搜索来说是一个至关重要的因素。
具体
从图相似性来的思路,c,e两个代码来自openssl不同编译器的结果,d是无关代码。将目标代码分割成更小的链,通过对比链的相似度推广到更大部分的相似度
合成相似性
将程序分解成较小的片段,称之为“链”,这些“链”来进行比较。
比较链使用“程序验证器”,传入相同的输入来检查中间值和输出值是否相同,不等同时会根据匹配值占总字符串总值来统计推理。
提出了一个统计推理算法,能根据链相似性推理整个程序的的相似性。
对比两条链的步骤
- 为两条链添加等价假设
- 下断言,检查所有输出变量的相等性
- 使用程序验证器检查断言,并计算有多少变量是等价的。
在假设和断言相等时,选择将哪些变量配对是通过搜索可能配对的空间来解决的。选择股作为一个小的比较单位(变量数量相对较少),再加上基于验证器的优化,可以大大缩小搜索空间,从而使验证器的使用变得可行。
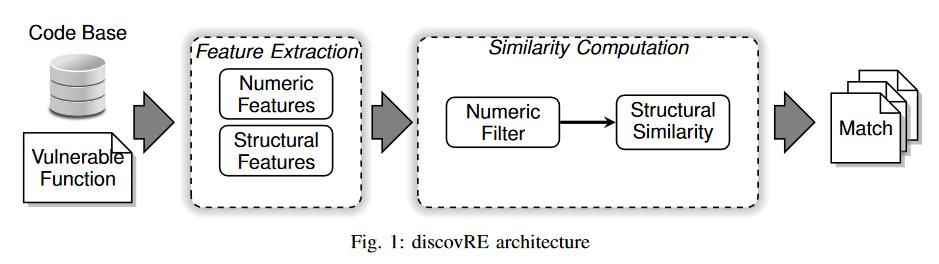
discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code14
tag: 2016,CCF-B/NDSS,基于数字特征过滤,kNN,MCS近似解
摘要
识别安全关键漏洞是保护计算机系统的关键。由于许多软件项目都是闭源的,因此能够在二进制级别执行这一过程是非常重要的。即使源代码是可用的,编译也可能造成源代码与处理器执行的二进制代码之间的不匹配,导致对源代码进行的分析无法检测到某些错误,从而发现潜在的漏洞。在二进制代码中查找漏洞的现有方法有:
-
使用动态分析,这对固件来说比较困难;
-
只处理单一架构;
-
使用语义相似性,这在分析大型代码库时非常缓慢。
在本文中,我们提出了一种在二进制代码中高效搜索相似函数的新方法。我们使用这种方法来识别二进制代码中的已知漏洞,具体如下:从一个易受攻击的二进制函数开始,我们在不同的编译器、优化级别、操作系统和 CPU 体系结构中识别其他二进制代码中的类似函数。其主要思路是根据相应控制流图的结构计算函数之间的相似性。为了尽量减少这种昂贵的计算,我们采用了一种基于数字特征的高效预过滤方法,以快速识别一小部分候选函数。这样,我们就能在大型代码库中高效地搜索类似函数。我们设计并实现了一种名为 discovRE 的方法原型,它支持四种指令集架构(x86、x64、ARM、MIPS)。我们的研究表明,在二进制文件中进行跨体系结构错误搜索时,discovRE 比最先进的学术方法快四个数量级。我们还表明,我们能在大约 80 毫秒内识别出 Android 系统映像中的 Heartbleed 和 POODLE 漏洞,该映像包含 130,000 多个原生 ARM 函数。
具体
基于机器学习算法和函数的一些统计特征信息和结构信息进行函数关联研究工作,定义了一些受不同架构影响较小的特征,然后给每一种特征赋予一定权重,根据数值特征过滤掉相差比较大的候选函数,然后计算函数之间的结构相似度,最终得到函数相似度的排名。对加了混淆的效果很差
特征
代码在不同编译器,优化选项,操作系统和CPU体系结构中代码特征分两种,结构特征,数字特征。结构特征就是内部控制流的结构,由CFG表示。这种特征是最稳健的特征,但是计算成本高,不适合比较大量函数。于是本文用第二种特征数字特征做为补充
数字特征代表二进制函数的元信息(指令数,基本模块数,局部变量大小),文章将数字特征嵌入向量空间,利用机器学习算法来根据特征查找相似函数。
对混淆差的原因就是混淆会增加指令与基本块,甚至会改变基本块结构,需要用其他方法提取
系统架构
首先通过IDA pro来提取数字特征与结构特征
相似性计算分两个过滤器,数字过滤器与结构过滤器,精度依次增高,计算复杂度也依次增高。所以先用数字过滤器筛选一部分再进入结构过滤器
数字特征过滤器
使用k-Nearest Neighbors算法(kNN)来查找相似函数,为了能比较自己确定了一组比较不同架构功能的特征
结构特征过滤器
检查CFG与数字过滤器的候选函数集,提出一种基于最大公共子图同构(MCS)的相似度量方法。(指定迭代次数,超过次数停止迭代,返回当前计算最小距离)
Scalable graph-based bug search for firmware images. 15
tag: 2016,CCF-A,ACFG,频谱聚类
摘要
由于物联网设备安全漏洞猖獗,在大规模物联网生态系统中搜索漏洞比以往任何时候都更加重要。最近的研究表明,基于控制流图(CFG)的漏洞搜索技术可以在不同架构的物联网设备中有效、准确地搜索漏洞。然而,这些基于 CFG 的错误搜索方法由于其昂贵的图匹配开销,远不能扩展到处理大量野生物联网设备。受图像和视频搜索领域丰富经验的启发,我们提出了一种新的错误搜索方案,该方案解决了现有跨平台错误搜索技术的可扩展性难题,并进一步提高了搜索精度。与直接基于二进制代码原始特征(CFG)进行搜索的现有技术不同,我们将 CFG 转换为高级数字特征向量。与 CFG 特征相比,高级数字特征向量对不同架构的代码变化具有更强的鲁棒性,而且可以通过使用最先进的哈希技术轻松实现实时搜索。我们实现了一个错误搜索引擎 Genius,并将其与最先进的错误搜索方法进行了比较。实验结果表明,对于各种查询负载,Genius 在速度和准确性方面都优于基准方法。我们还在一个由 33,045 台设备组成的真实数据集上对 Genius 进行了评估,该数据集是从公共资源和我们的系统中收集的。实验结果表明,在对 8,126 张固件图片(包含 420,558,702 种功能)进行搜索时,Genius 可以在平均 1 秒内完成搜索。通过只查看搜索结果中的前 50 个候选对象,我们发现了 5 个供应商的 38 个潜在漏洞固件映像,并通过人工分析确认了其中的 23 个。我们还发现,在 D-LINK 最新推出的两款商用固件镜像中,平均只需 0.1 秒就能搜索完所有 154 个漏洞。这些镜像中有 103 个潜在漏洞,其中 16 个已被确认。
具体
该方法利用统计特征构建函数的ACFG(Attributed CFG),然后将若干函数的ACFG进行聚类,得到n个类心,使用类心对每个ACFG进行编码,使每个函数对应一个编码向量。然后利用向量计算函数之间的相似度。该方法虽然具有可扩展性,但是离线聚类算法时间耗费非常大。
特征相似性定义
归属控制流图(ACFG)是一个有向图\(G=<V, E, \varphi>\),可以直接用ACFG图来计算相似度量。
聚类
用 频谱聚类算法作为无监督学习算法来生成代码集,生成代码集的成本很高,不过可以前期学习阶段生成,可以用近似聚类/分层聚类算法来加快
特征编码
特征编码就是将原始特征(ACFG)映射到学习后的代码集
特征编码有两个显著的好处。首先,高层次特征能更好地容忍不同架构下函数的变化,因为它的每个维度都是分类的相似性关系,而分类对二元函数变化的敏感度低于 ACFG 本身。
Cross-Architecture Binary Semantics Understanding via Similar Code Comparison16
tag: 2016,CCF-B
摘要
随着智能设备(如智能手机、路由器、摄像头)的普及,越来越多的程序从传统的桌面平台移植到 ARM 或 MIPS 架构的嵌入式硬件上。虽然由于 CPU 架构的不同,编译后的二进制代码也大不相同,但这些移植程序共享桌面版的代码库。因此,利用商品计算机的程序来帮助理解这些交叉编译的二进制代码并查找具有相似语义的函数是可行的。然而,由于不同体系结构的指令集通常是不可比的,因此很难进行静态的跨体系结构二进制代码相似性比较。为此,我们提出了一种基于语义的方法来实现这一目标。我们以相同的方式从不同平台上的二进制代码中动态提取签名,签名由条件操作行为和系统调用信息组成。然后测量签名的相似性,以帮助识别移植程序中的函数。我们在 MOCKINGBIRD 中实现了这一方法,MOCKINGBIRD 是一种自动分析工具,用于比较不同架构二进制文件之间的代码相似性。MOCKINGBIRD 支持主流架构,能够分析 Linux 平台上的 ELF 可执行文件。我们用一组交叉编译版本的流行程序对 MOCKINGBIRD 进行了评估。结果表明,我们的方法不仅能有效处理跨体系结构二进制代码比较这一新问题,而且由于利用了语义信息,还提高了基于相似性的函数识别的准确性。
具体
主要是依赖于本文提取出来的语义签名,来对比二进制文件间的语义;同时还利用了VEX-IR,转换汇编成中间代码,更好的提取语义与对比
语义签名
主要用COP喝SCA的概念来定义语义特征,COP是比较指令的操作数值对,它在执行中引入条件测试,并决定后续分支指令的跳转目标。比如下图中IA-32的cmp [ebp+arg_0], 0,[ebp+arg_0], 0的值就是COP,这两个值的比较结果决定是否跳转. 比较指令奖控制依赖关系转换为数据依赖关系,
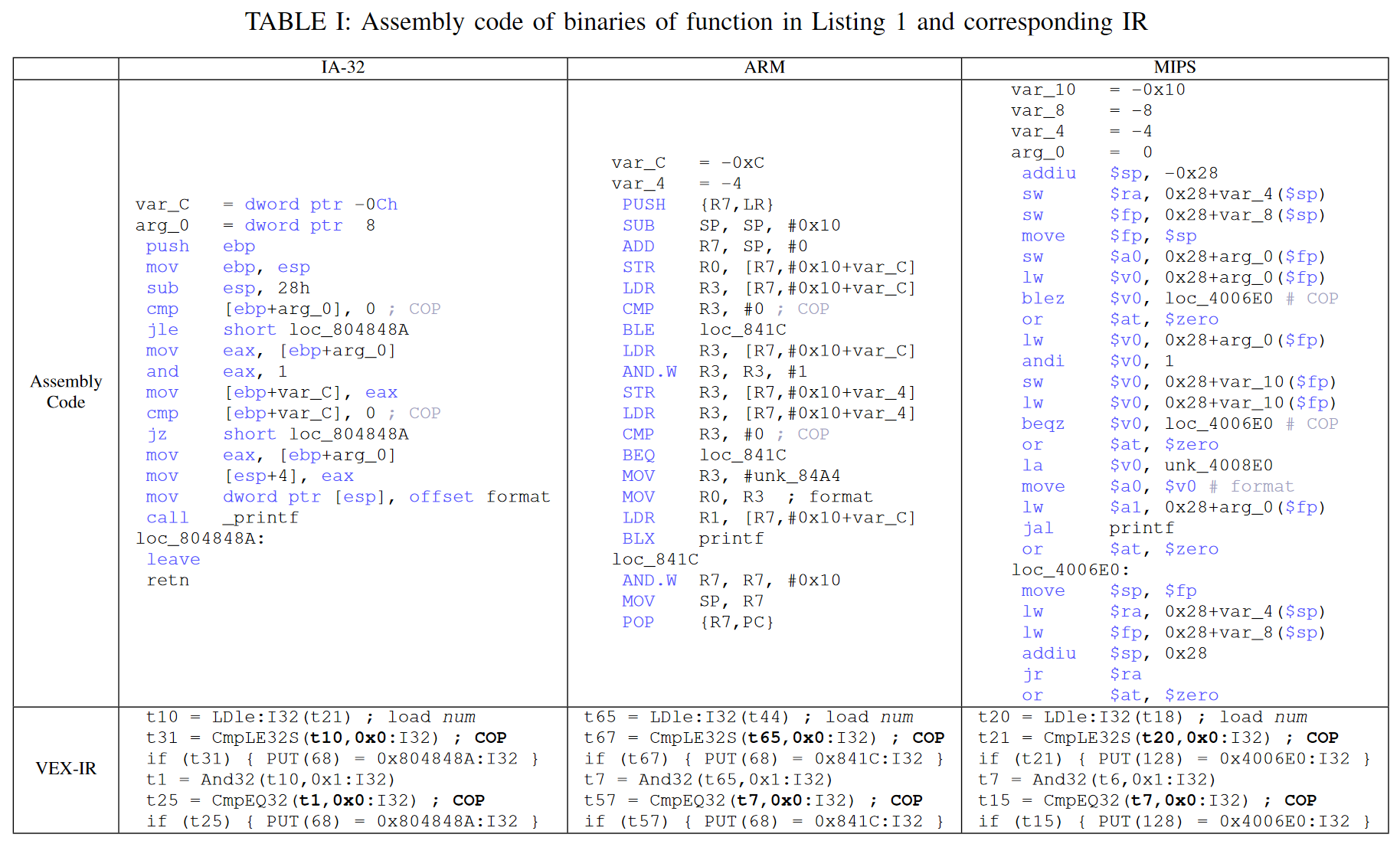
对应的代码如下,如果num=5,那么无论那个架构的COP序列都是{(5,0),(1,0)}

语义签名还有SCA,SCA是由执行中调用的系统调用名称喝参数组成,下图就是上图的系统调用

系统调用有一些是指针,所以需要提取出指针对应的数据。然后文章就是提取指针数据,压缩数据,规范指针的一些操作。序列样式如下
0x00000001 0x00000027
0x00000005 0x00000005
序列相似性比较
对比序列有很多算法,这篇文章使用的是最长公共序列(LCS),使用jaccard指数计算序列A和B的相似度。\(|A\cap B|\)表示他们的LCS长度,\(|A|,|B|\)分别表示A和B的长度 $$ J(A,B) = \frac{|A\cap B|}{|A\cup B|}=\frac{|A\cap B|}{|A|+|B|-|A\cap B|} $$
参考
-
Jiyong Jang, David Brumley, and Shobha Venkataraman. 2011. Bitshred: feature hashing malware for scalable triage and semantic analysis. In Proceedings of the 18th ACM conference on Computer and communications security. 309–320. https://doi.org/10.1145/2046707.2046742 ↩︎
-
Wesley Jin, Sagar Chaki, Cory Cohen, Arie Gurfinkel, Jeffrey Havrilla, Charles Hines, and Priya Narasimhan. 2012. Binary function clustering using semantic hashes. In 2012 11th International Conference on Machine Learning and Applications, Vol. 1. IEEE, 386–391. https://doi.org/10.1109/ICMLA.2012.70 ↩︎
-
Martial Bourquin, Andy King, and Edward Robbins. 2013. Binslayer: accurate comparison of binary executables. In Proceedings of the 2nd ACM SIGPLAN Program Protection and Reverse Engineering Workshop. 1–10. https://doi.org/10.1145/2430553.2430557 ↩︎
-
Silvio Cesare, Yang Xiang, and Wanlei Zhou. 2013. Control flow-based malware variant detection. IEEE Transactions on Dependable and Secure Computing 11, 4 (2013), 307–317. https://doi.org/10.1109/TDSC.2013.40 ↩︎
-
Xin Hu, Kang G Shin, Sandeep Bhatkar, and Kent Griffin. 2013. {MutantX-S}: Scalable Malware Clustering Based on Static Features. In 2013 USENIX Annual Technical Conference (USENIX ATC 13). 187–198. rtcl.eecs.umich.edu/papers/publications/2013/MutantX-S.pdf ↩︎
-
Lannan Luo, Jiang Ming, Dinghao Wu, Peng Liu, and Sencun Zhu. 2014. Semantics-based obfuscation-resilient binary code similarity comparison with applications to software plagiarism detection. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. 389–400. https://doi.org/10.1145/2635868.2635900 ↩︎
-
Jannik Pewny, Felix Schuster, Lukas Bernhard, Thorsten Holz, and Christian Rossow. 2014. Leveraging semantic signatures for bug search in binary programs. In Proceedings of the 30th Annual Computer Security Applications Conference. 406–415. https://doi.org/10.1145/2664243.2664269 ↩︎
-
Aylin Caliskan, Fabian Yamaguchi, Edwin Dauber, Richard Harang, Konrad Rieck, Rachel Greenstadt, and Arvind Narayanan. 2015. When coding style survives compilation: De-anonymizing programmers from executable binaries. arXiv preprint arXiv:1512.08546 (2015). https://doi.org/10.48550/arXiv.1512.08546 ↩︎
-
Jannik Pewny, Behrad Garmany, Robert Gawlik, Christian Rossow, and Thorsten Holz. 2015. Cross-architecture bug search in binary executables. In 2015 IEEE Symposium on Security and Privacy. IEEE, 709–724. https://doi.org/10.1109/SP.2015.49 ↩︎
-
Mahinthan Chandramohan, Yinxing Xue, Zhengzi Xu, Yang Liu, Chia Yuan Cho, and Hee Beng Kuan Tan. 2016. Bingo: Crossarchitecture cross-os binary search. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. 678–689. https://doi.org/10.1145/2950290.2950350 ↩︎
-
Yaniv David, Nimrod Partush, and Eran Yahav. 2016. Statistical similarity of binaries. Acm Sigplan Notices 51, 6 (2016), 266–280. https://doi.org/10.1145/2908080.2908126 ↩︎
-
Sebastian Eschweiler, Khaled Yakdan, and Elmar Gerhards-Padilla. 2016. discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code.. In NDSS, Vol. 52. 58–79. https://doi.org/10.14722/ndss.2016.23185 ↩︎
-
Qian Feng, Rundong Zhou, Chengcheng Xu, Yao Cheng, Brian Testa, and Heng Yin. 2016. Scalable Graph-based Bug Search for Firmware Images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘16). Association for Computing Machinery, New York, NY, USA, 480–491. https://doi.org/10.1145/2976749.2978370 ↩︎
-
Yikun Hu, Yuanyuan Zhang, Juanru Li, and Dawu Gu. 2016. Crossarchitecture binary semantics understanding via similar code comparison. In 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Vol. 1. IEEE, 57–67. https://doi.org/10.1109/SANER.2016.50 ↩︎