智能合约代码混淆,感觉还是ollvm的影子,还是那三种模式,只是做了相关的适配以及加了很多其他细节,总体思路是没有变的。
创新点在于使用改进后的混沌映射来做不透明谓词,增加了一定的混淆程度
会议:IEEE Transactions on Software Engineering
等级:CCF-A
这篇文章聚焦的领域是智能合约代码混淆,首先说说智能合约代码现状的一些问题。
首先代码是公开的,不容易及时更改的。是很容易可以反编译得到源码的,这增加了漏洞发现的风险。那么现有的智能合约代码安全方面的工作主要集中在源码级别或者字节码级别的漏洞检测,属于静态分析和动态分析
本文是从另一个角度增加智能合约代码的安全性,通过混淆代码,减少被漏洞挖掘的可能。同时混淆代码还可以用于保护知识产权(比如在源码中插入验证知识产权的代码,混淆后很难被识别出来并删除)
混淆从三个角度来混淆
- 控制流混淆
- 数据流混淆
- 布局混淆
控制流混淆
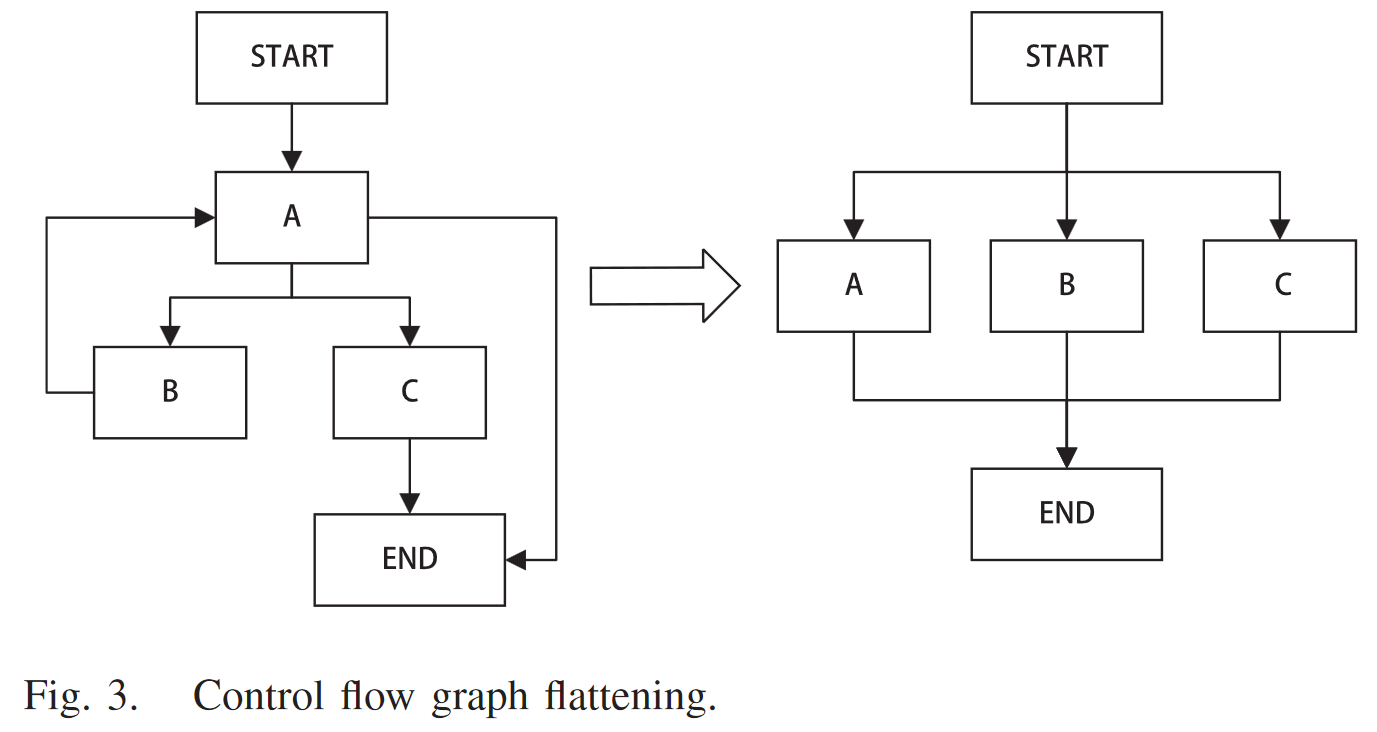
控制流混淆主要有两个部分,不透明谓词和控制流平坦化
控制流平坦化
这个是ollvm经典的混淆模式,也是目前在通用领域效果最好的混淆模式之一
不透明谓词
不透明谓词是生成一些逻辑上永真或者永假效果的复杂表达式,人可以很快分辨出来,但是编译器或者说静态分析器无法推断出这个值,只能在运行时确定。
y > 10 || x * (x + 1) % 2 == 0这是一个永真式
插入不透明谓词主要的效果是增加一些虚假的控制流。
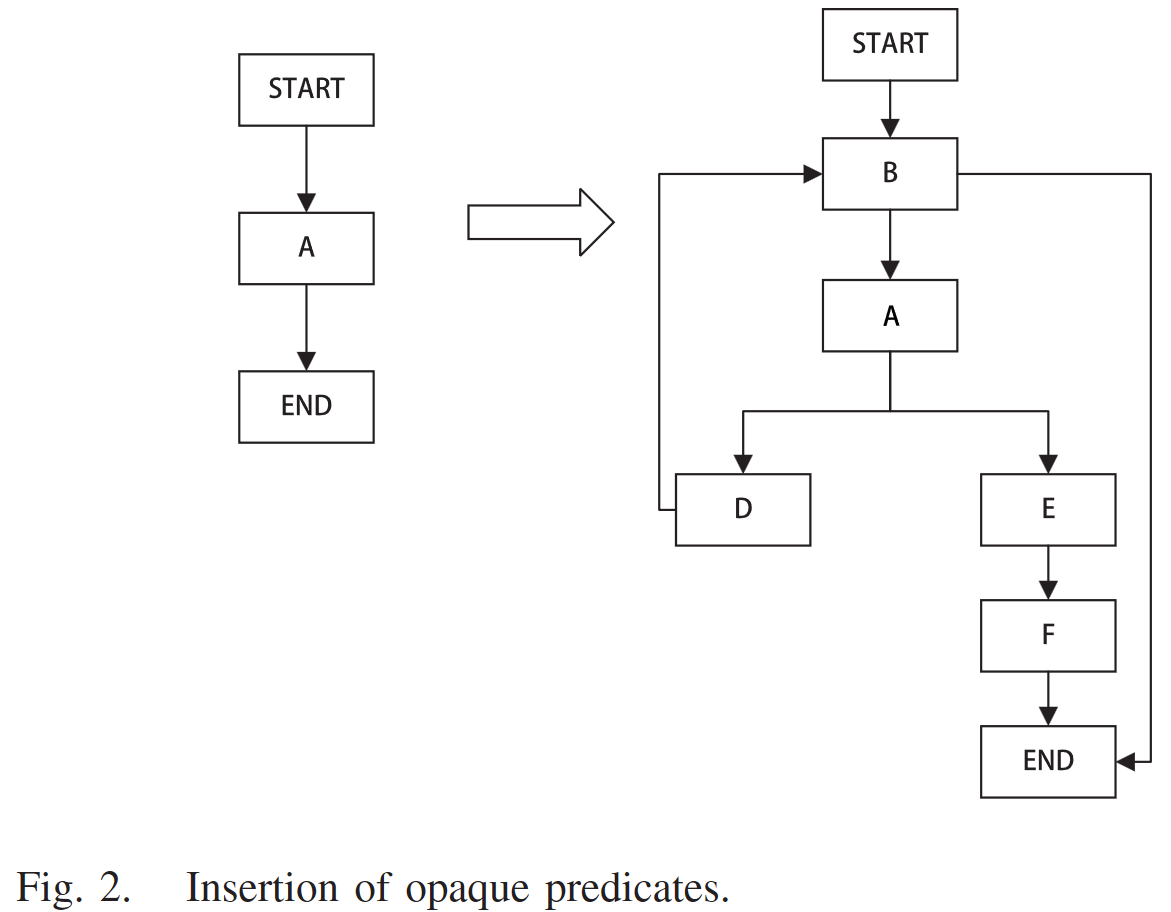
本文提出一种构造不透明谓词的CPM混沌映射来提高不透明谓词的质量。CPM混沌映射基于Chebyshev和PWLCM混沌映射改进,保留混沌映射的敏感和随机性的同时提高了性能
可以理解CPM混沌映射会生成一个伪随机数范围0-1,每次生成都不一样。论文将混沌映射与不透明谓词结合,关键的等式是生成的伪随机数接近1就为真,接近0则为假。这个可以根据项目开发具体的修改来修改
数据流混淆
主要就是加密程序中的数据部分。
通过提取AST语法树中的节点,识别出数据在进行混淆,主要混淆有如下几点
- 把局部变量转全局变量
- 将静态数据转换成动态数据
- 将整数常数转换成算数表达式
- 拆分布尔变量:如果原本为
true则后续接一个||和后续表达式,false则是&&接后续表达式 - 将标量变量转成向量:在结构体中集体声明整数、布尔、地址、字符串和字节等状态变量,并通过结构体调用成员变量。原有状态变量的所有初始化、赋值和使用都将被相应的结构成员变量替换。替换后的变量名和函数名都是用SHA-1生成原本名称的摘要
布局混淆
主要是对代码中的一些标识符和调试信息增加干扰。
- 删除注释,打乱布局:使用无意义的字符串来替换
- 替换变量名:SHA-1
混淆效果
最后看一下混淆的效果
